After choosing the best suitable algorithm and working with high-quality data, you may have finally touched the milestone of training your AI model.
Congratulations on this feat!
But most tutorials end at this point – so, now what?
Before you start the celebrations and call it a day, know that this is just the starting point! After all, even the best trained AI models prove to be useless if you cannot apply them to practical settings.
As a matter of fact, now is when you will face your first major challenge – incorporating your AI models in real-world settings to make predictions on future outcomes to drive value and decision making.
So, once you have tried, tested, and streamlined your model, the following is the next stage:
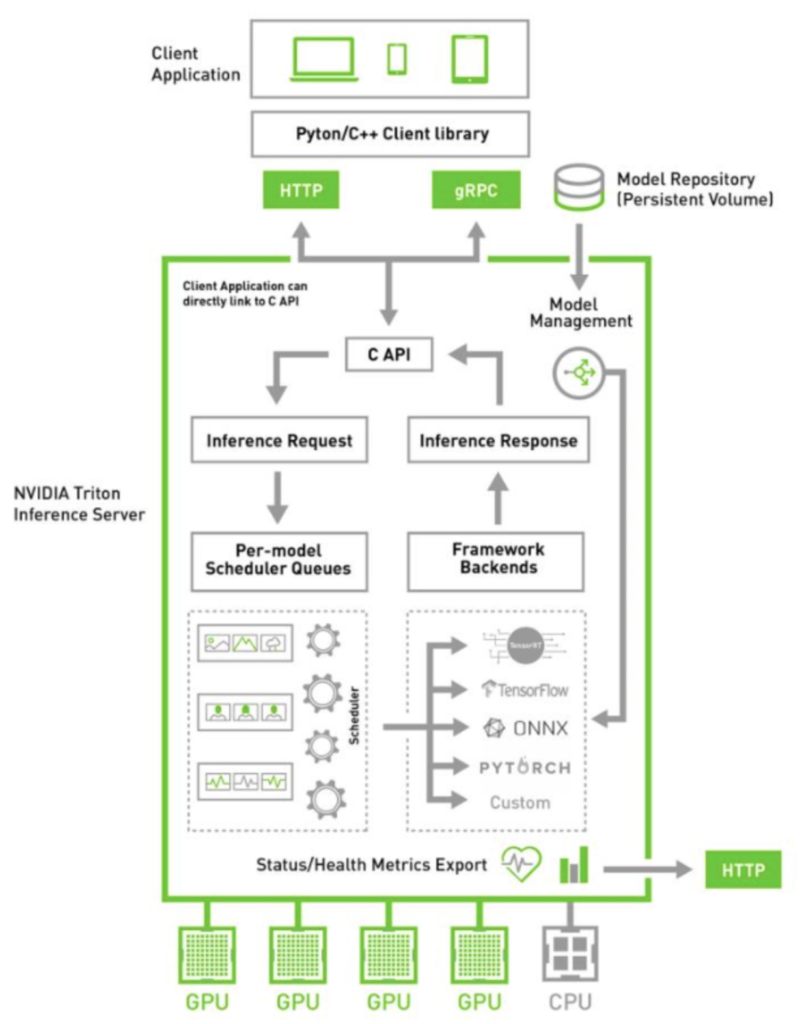
Client Inference
Inference is the process of using a trained AI model to make a prediction.
But how is it different from training?
Inference is essentially the application of the AI models on new data sets to solve real-life business problems. Here, your trained AI model can treat data from endpoints like IoT devices and sensors as inputs (rather than source training data) to make predictions and guide decision logic. This decision-making can occur on edge devices, on-premise gateways, or cloud-hosted devices, also known as inference servers or inference engines.
They can also serve as self-learning, self-correcting mechanisms that can discover the root cause behind recurring issues and problems to take action against them.
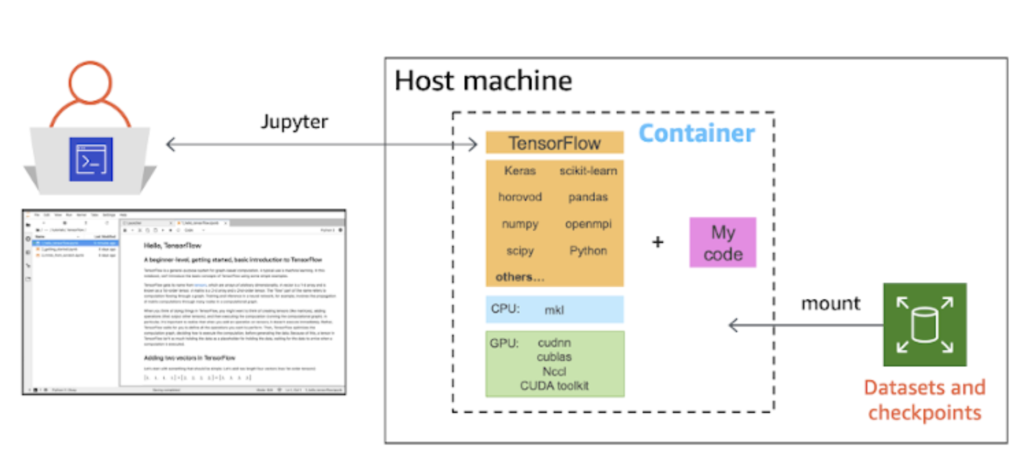
Containerization
While client inference takes care of AI serving, containerization takes care of the reproducibility of the model. It also adds other benefits in the form of making efficient use of resources, bypassing repetitive tasks, and speeding up the model and server response.
But to achieve these benefits, you need to first put your trained AI model in a container before deploying it. The Kubernetes-Docker combination would be the commonest tool combination that you may have come across for this task. Essentially, you will have to build a container for your trained AI model using Docker and orchestrate it through Kubernetes. This process will also allow your machine to scale and stay resilient during deployment.
Deployment
And finally, this is the moment you have been waiting for – deployment.
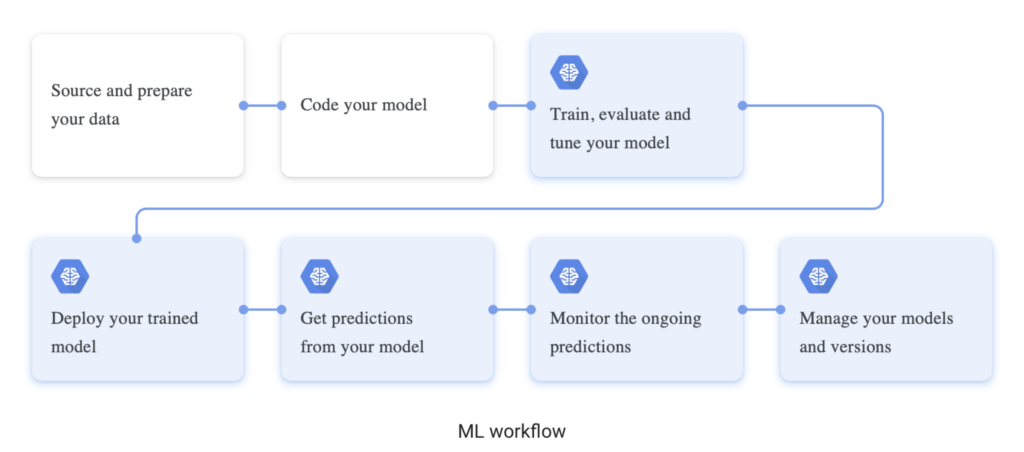
The tools and environments that you choose while deploying trained model APIs will govern the production capabilities. Against this background, the concept of CI/CD (Continuous Integration/Continuous Delivery or Deployment) paves the way for AIOps. You may have heard of deployment through tools like Cortex, Datadog, AppDynamics, or Kubeflow that facilitate serving.
And once you have worked out these details, it is about choosing whether you deploy on the cloud or at the edge (directly on devices). The former needs no introduction (Google AI Platform, Microsoft Azure, TensorFlow being industry leaders), while the latter is the newest entrant that is making news. Edge deployment encompasses improved privacy, lower cost, real-time capabilities, and a smaller footprint. However, data transferring and storage can be a constraint in the adoption of this option.
Final Thoughts
If you find yourself in the “what is next?” stage, you are not alone. According to Gartner, about 47% of businesses experience difficulty deploying into business processes that inhibit business value delivery.
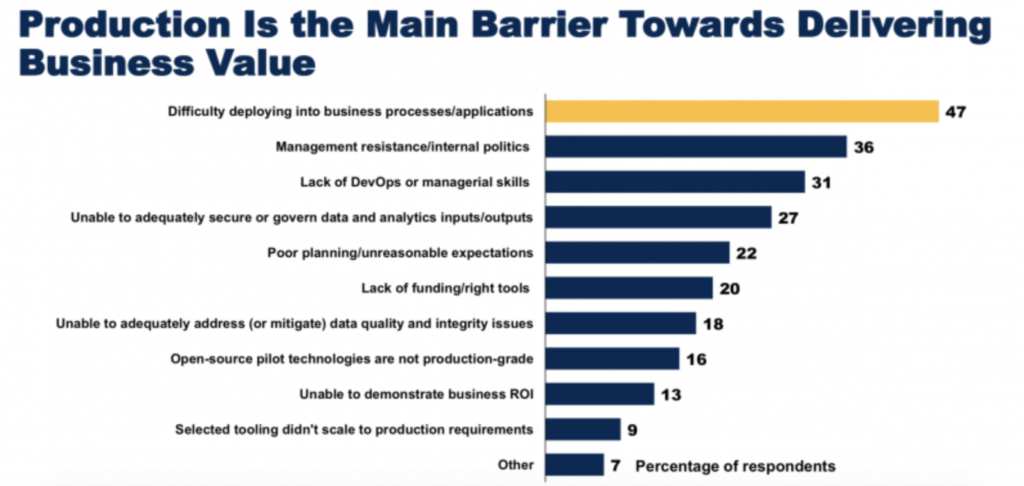
Fortunately, the above roadmap can help you get started to actualize your vision and commence production!


